Development of NLP-Powered Classificator of Job Application Emails Using Scikit-learn Library
This project presents a production-oriented Natural Language Processing (NLP) email classification system designed to assist job seekers in organizing and interpreting recruitment-related email communication. Built with Python and Scikit-learn, the application automatically classifies emails into meaningful categories such as Invitation, Rejection, Confirmation, or Non job-hunt related, significantly reducing manual effort during job searches. The system supports two complementary classification architectures: the three-stage binary pipelines, where emails are progressively filtered through specialized models (job-related detection → confirmation detection → invitation vs rejection); and a multiclassifier pipeline, capable of predicting all classes directly using a single model. Both approaches are implemented using modular Scikit-learn pipelines with TF-IDF vectorization and a flexible classifier registry supporting a wide range of algorithms, including Naive Bayes, Logistic Regression, SVMs, ensemble methods, and meta-classifiers such as VotingClassifier and StackingClassifier.
Self paced project, 10.2025 - 01.2026
Gallery
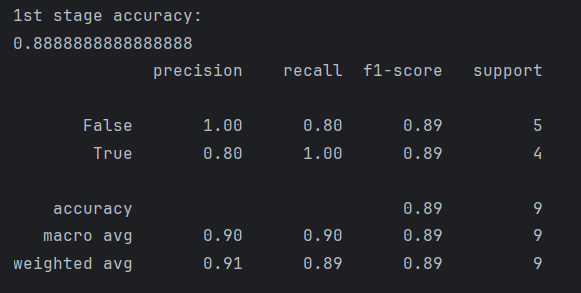
Accuracy of first stage of 3-stage-classifier.
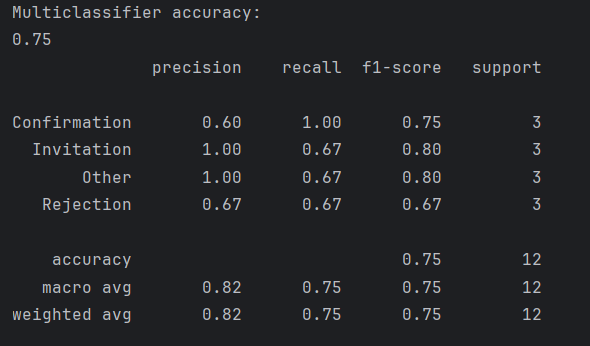
Accuracy of multiclassifier.
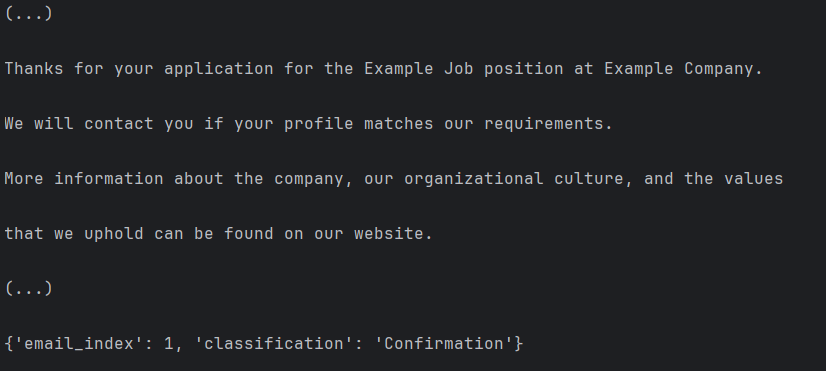
Prediction of a confirmation email.
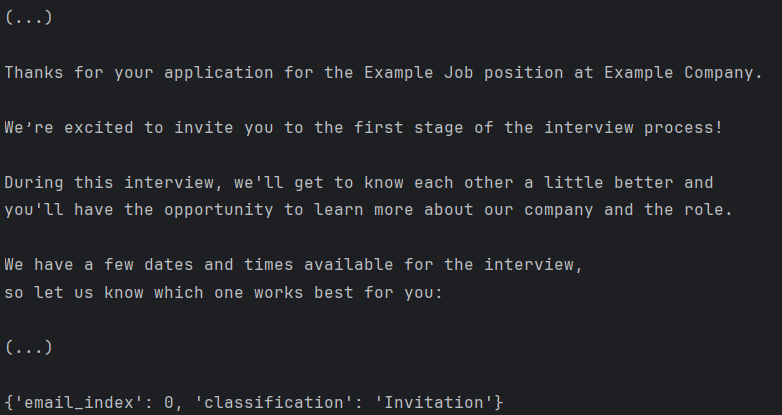
Prediction of an invitation email.
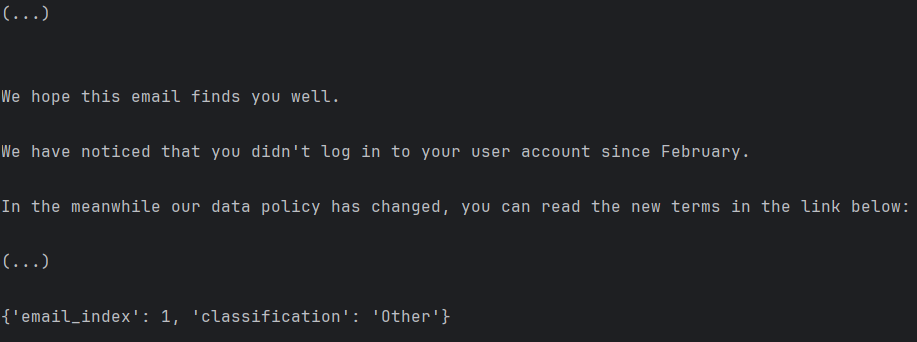
Prediction of an email not connected to jobhunt.
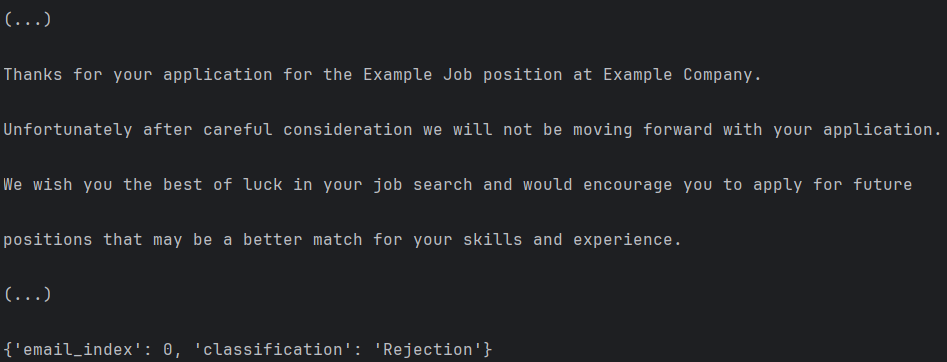
Prediction of a rejection email.

Example of a training data for a three-stage classifier to diverse jobhunt emails from other.
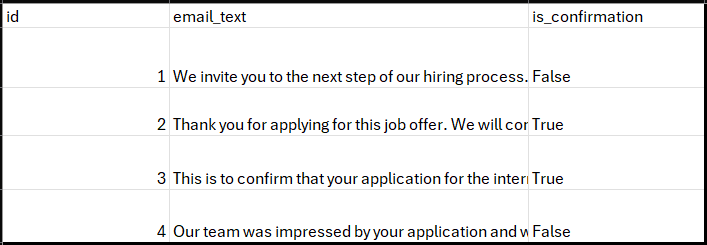
Example of a training data for a three-stage classifier to diverse confirmation emails from other categoies.
Example of a training data for a three-stage classifier to diverse invitation emails from other categoies.
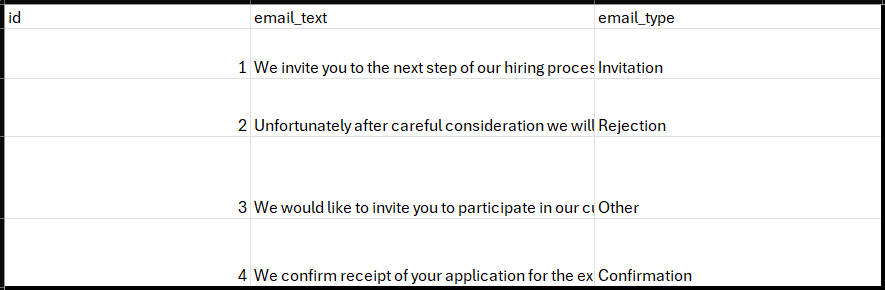
Example of a training data for a multiclassifier.
Project Results
- Designed and implemented a fully functional NLP-based email classification system tailored for job-hunting.
- Successfully built two independent classification architectures: a three-stage pipeline for step-by-step decision making and a multiclassifier pipeline for direct multi-label prediction.
- Integrated TF-IDF vectorization with multiple machine learning classifiers using Scikit-learn pipelines.
- Implemented support for following classifiers options: MultinomialNB, ComplementNB, BernoulliNB, LogisticRegression, SGDClassifier, RidgeClassifier, LinearSVC, SVC, KNeighborsClassifier, DecisionTreeClassifier, ExtraTreeClassifier, RandomForestClassifier, GradientBoostingClassifier, AdaBoostClassifier, VotingClassifier (only for multiclassifier), StackingClassifier (only for multiclassifier).
- Developed a flexible classifier registry, enabling easy extension and configuration of models without modifying core logic.
- Implemented robust custom exception handling, ensuring predictable behavior and clear error reporting for invalid inputs and configurations.
- Conducted extensive unit tests using mocking and parameterized testing, without reliance on real data or trained models; verified correct behavior for all execution paths, including success routes and all exception branches.
- Generated automated API documentation using Sphinx, covering source code and test modules.
- Applied clean architecture principles, resulting in modular, readable, and maintainable code suitable for further development.
See the source code and documentation:

